
Source: Arm Author: Arm
With the introduction of artificial intelligence (AI), especially generative AI, the automotive industry is undergoing a transformative transformation. A recent survey conducted by McKinsey among automotive and manufacturing executives shows that over 40% of the respondents have invested as much as 5 million euros in the research and development of generative AI, and over 10% have invested more than 20 million euros.
As the industry continues to evolve towards software-defined vehicles (SDVS), the number of lines of code in a car is expected to increase from 100 million lines per vehicle to approximately 300 million lines by 2030. The combination of generative AI for automobiles and SDV can jointly achieve in-vehicle use cases in terms of performance and comfort, helping to enhance the driving and riding experience.
This article will introduce an in-vehicle generative AI use case developed by Arm in collaboration with Amazon Web Services (AWS) and its implementation details.
Introduction to Use Cases
As cars become increasingly sophisticated, car owners can now continuously receive updates to features such as parking assistance or lane keeping after delivery. The challenge that comes along is how to keep car owners informed of the new updates and features in a timely manner. The past update methods through traditional means such as paper or online manuals have proved to have deficiencies, resulting in car owners being unable to fully understand the potential of their vehicles.
To address this challenge, AWS has combined the powerful capabilities of generative AI, edge computing, and the Internet of Things (IoT) to develop a demonstration of in-vehicle generative AI. The solution presented in this demonstration is an in-vehicle application supported by a small language model (SLM), designed to enable drivers to obtain the latest vehicle information through natural voice interaction. This demonstration application can run offline after deployment, ensuring that drivers can access important information about the vehicle even without an Internet connection.
This solution integrates multiple advanced technologies to create a more seamless and efficient product experience for users. The application of this demonstration is deployed in a local small language model in the vehicle, which improves performance by using routines optimized by Arm KleidiAI. The response time of the system not optimized by KleidiAI is about 8 to 19 seconds. In contrast, the reasoning response time of the small language model optimized by KleidiAI is 1 to 3 seconds. By using KleidiAI, the application development time has been shortened by 6 weeks, and developers do not need to focus on the optimization of the underlying software during the development period.
Arm Virtual Hardware supports access to many popular Internet of Things development kits on AWS. When physical devices are unavailable or teams around the world cannot access them, developing and testing on Arm virtual hardware can save the development time of embedded applications. AWS successfully tested this demonstration application on the automotive virtual platform. In the demonstration, Arm virtual hardware provided a virtual instance of the Raspberry PI device. The same KleidiAI optimization can also be applied to Arm virtual hardware.
One of the key features of this generative AI application running on edge-side devices is that it can receive OTA wireless updates, some of which are received using AWS IoT Greengrass Lite, thereby ensuring that the latest information is always provided to the driver. The AWS IoT Greengrass Lite occupies only 5 MB of RAM on edge-side devices, thus having a very high memory efficiency. In addition, this solution includes automatic quality monitoring and feedback loops for continuously evaluating the relevance and accuracy of the responses of small language models. Among them, a comparison system was adopted to mark the responses that exceeded the expected quality threshold for review. Then, through the dashboard on AWS, the collected feedback data is visualized at near real-time speed, enabling the quality assurance team of the vehicle manufacturer to review and identify areas that need improvement and initiate updates as necessary.
The advantage of this solution supported by generative AI lies not only in providing accurate information for drivers. It also reflects a paradigm shift in SDV lifecycle management, achieving a more continuous improvement cycle. Vehicle manufacturers can add new content based on user interaction, while small language models can be fine-tuned using update information seamlessly deployed via wireless networks. In this way, by ensuring the latest vehicle information, the user experience is enhanced. Additionally, vehicle manufacturers also have the opportunity to introduce and guide users on new features or additional functions that can be purchased. By leveraging the powerful capabilities of generative AI, the Internet of Things (iot), and edge computing, this generative AI application can serve as a guide for automotive users. The methods demonstrated here contribute to achieving a more connected, information-based, and adaptable driving experience in the SDV era.
End-to-end upper-layer implementation scheme
The solution architecture shown in the following figure is used for fine-tuning the model, testing the model on Arm virtual hardware, and deploying small language models to edge-side devices, and it includes a feedback collection mechanism.

The numbers in the above picture correspond to the following contents:
1. Model fine-tuning: The AWS demonstration application development team chose TinyLlama-1.1B-Chat-v1.0 as its base model, which has been pre-trained for session tasks. To optimize the car user guide chat interface for drivers, the team designed concise and focused responses to adapt to the situation where drivers can only free up limited attention while driving. The team created a custom dataset containing 1,000 groups of questions and answers and fine-tuned it using Amazon SageMaker Studio.
2. Storage: The tuned small language model is stored in the Amazon Simple Storage Service (Amazon S3).
3. Initial Deployment: The small language model is initially deployed to the Ubuntu-based Amazon EC2 instance.
4. Development and Optimization: The team developed and tested a generative AI application on EC2 instances, quantified small language models using llama.cpp, and applied the Q4_0 solution. KleidiAI optimization is pre-integrated with llama.cpp. Meanwhile, the model has also achieved significant compression, reducing the file size from 3.8GB to 607MB.
5. Virtual Testing: Transfer the application and small language model to the virtual Raspberry PI environment of Arm virtual hardware for initial testing.
6. Virtual verification: Conduct a comprehensive test in a virtual Raspberry PI device to ensure it functions properly.
7. Edge-side deployment: Deploy generative AI applications and small language models to physical Raspberry PI devices by using AWS IoT Greengrass Lite, and manage the deployment using AWS IoT Core jobs.
8. Deployment Orchestration: AWS IoT Core is responsible for managing the tasks deployed to the Raspberry PI devices on the edge side.
9. Installation process: AWS IoT Greengrass Lite processes the software packages downloaded from Amazon S3 and automatically completes the installation.
10. User Interface: The deployed application provides voice-based interaction functions for end users on the edge Raspberry PI device.
11. Quality Monitoring: Generative AI applications enable quality monitoring of user interaction. Data is collected through AWS IoT Core, processed through Amazon Kinesis Data Streams and Amazon Data Firehose, and then stored in Amazon S3. Vehicle manufacturers can monitor and analyze data through the Amazon QuickSight dashboard to promptly identify and resolve any quality issues of small language models.
Next, we will delve into KleidiAI and the quantification scheme adopted in this demonstration.
Arm KleidiAI
Arm KleidiAI is an open-source library specifically designed for developers of AI frameworks. It provides optimized performance-critical routines for Arm cpus. This open-source library was initially launched in May 2024 and now provides optimization for matrix multiplication of various data types, including ultra-low precision formats such as 32-bit floating-point, Bfloat16, and 4-bit fixed-point. These optimizations support multiple Arm CPU technologies, such as SDOT and i8mm for 8-bit computing, and MLA for 32-bit floating-point operations.With four Arm Cortex-A76 cores, the Raspberry PI 5 demonstration uses KleidiAI's SDOT optimization. SDOT is one of the earliest instructions designed for AI workloads based on Arm cpus and was introduced in Armv8.2-A released in 2016.
The SDOT instruction also demonstrates Arm's continuous commitment to enhancing AI performance on cpus. Following SDOT, Arm has gradually introduced new instructions for running AI on cpus, such as i8mm for more efficient 8-bit matrix multiplication and Bfloat16 support, with the aim of enhancing 32-bit floating-point performance while halving memory usage.
For the demonstration using Raspberry PI 5, KleidiAI plays a key role in accelerating matrix multiplication by using the block quantization scheme and integer 4-bit quantization (also known as Q4_0 in llama.cpp).
The Q4_0 quantization format in llama.cpp
The Q4_0 matrix multiplication in llama.cpp consists of the following components:
The left (LHS) matrix stores the activation content in the form of 32-bit floating-point values.
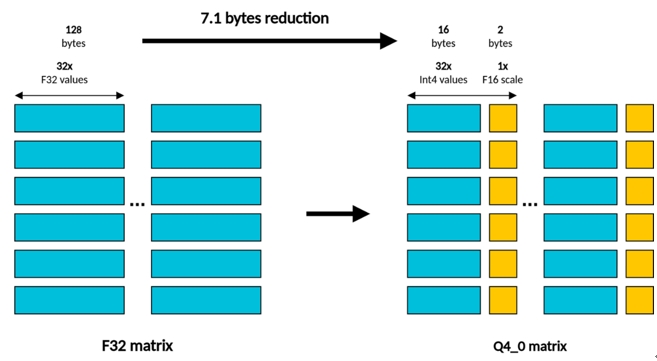
The right (RHS) matrix contains the weights of the 4-bit fixed-point format. In this format, the quantization scale is applied to a data block composed of 32 consecutive 4-bit integer values and encoded using 16-bit floating-point values.
At this stage, neither the LHS nor the RHS matrix is in 8-bit format. How does KleidiAI utilize the SDOT instruction specifically designed for 8-bit integer dot products? Both of these input matrices must be converted to 8-bit integer values.
For the LHS matrix, an additional step is required before the matrix multiplication process: dynamic quantization to an 8-bit fixed-point format. This process uses the block quantization scheme to dynamically quantify the LHS matrix into 8 bits. Among them, the quantization scale is applied to the data blocks composed of 32 consecutive 8-bit integer values and is stored in the form of 16-bit floating-point values, which is similar to the 4-bit quantization method.
Dynamic quantization can minimize the risk of decreased accuracy because the quantization scale factor is calculated based on the minimum and maximum values in each data block during reasoning. In contrast to this method, the scale factor of static quantization is pre-determined and remains unchanged.
For the RHS matrix, no additional steps are required before the matrix multiplication process. In fact, 4-bit quantization serves as the compression format, while the actual calculation is carried out in 8-bit format. Therefore, before passing the 4-bit value to the dot product instruction, it is first converted to 8 bits. The computational cost of converting from 4 bits to 8 bits is not high because only simple shift/mask operations are required.
Since the conversion efficiency is so high, why not directly use 8-bit to avoid the trouble of conversion?
Reduce model size: Since the memory required for a 4-bit value is only half that of an 8-bit value, this is particularly beneficial for platforms with limited available RAM.
Improving text generation performance: The text generation process relies on a series of matrix and vector operations, which are usually limited by memory. That is to say, performance is limited by the data transfer speed between memory and the processor, rather than the computing power of the processor. Since memory bandwidth is a limiting factor, reducing the data size can minimize memory traffic to the greatest extent, thereby significantly improving performance.
How to combine the use of KleidiAI and llama.cpp?
It's very simple. KleidiAI has been integrated into llama.cpp. Therefore, developers can fully leverage the performance of Arm cpus in ARM V8.2 and later architecture versions without the need for additional dependencies.
The integration of the two means that developers running llama.cpp on mobile devices, embedded computing platforms, and servers based on Arm architecture processors can now experience better performance.
Are there any other options besides llama.cpp?
For running large language models on Arm cpus, although llama.cpp is a good choice, developers can also use other high-performance generative AI frameworks optimized by KleidiAI. For example (in alphabetical order) : ExecuTorch, MediaPipe, MNN and PyTorch. Just select the latest version of the framework.
Therefore, if developers are considering deploying generative AI models on Arm cpus, exploring the above framework is helpful for optimizing performance and efficiency.
Summary
The integration of SDV and generative AI is jointly ushering in a new era of automotive innovation, making future cars more intelligent and user-centered. The in-vehicle generative AI application demonstration introduced in the article is optimized by Arm KleidiAI and supported by the services provided by AWS, demonstrating how emerging technologies can help address the practical challenges in the automotive industry. This solution can achieve a response time of 1 to 3 seconds and shorten the development time by several weeks, demonstrating that more efficient and offline available generative AI applications can not only be realized but are also highly suitable for in-vehicle deployment.
The future of automotive technology lies in creating solutions that seamlessly integrate edge computing, Internet of Things (iot) functions and AI. As automobiles continue to evolve and software becomes increasingly complex, potential solutions (such as the one introduced in this article) will be the key to bridging the gap between advanced automotive functions and users' understanding.
Therefore, when referring to the multiplication of 4-bit integer matrices, it specifically refers to the format used for weights, as shown in the following figure:
免责声明: 本文章转自其它平台,并不代表本站观点及立场。若有侵权或异议,请联系我们删除。谢谢! Disclaimer: This article is reproduced from other platforms and does not represent the views or positions of this website. If there is any infringement or objection, please contact us to delete it. thank you! |

WeChat Official Account

WeChat Service
 Email
Email QQ
QQ 13823761625
13823761625
