
Author: Dr. Gunar Lorenz Senior Director, Technical Marketing, Infineon Technologies
Proofread: Chief Engineer, Consumer, Computing and Communication Business, Greater China, Infineon Technology
introduction
At Infineon, we have always believed that superior audio solutions are essential to enhance the user experience on consumer devices. We are proud of our unwavering commitment to innovation and the significant advances we have made in active noise reduction, voice transmittance, studio recording, audio zoom and other related technologies. As a leading supplier of MEMS microphones, Infineon focuses its resources on improving the audio quality of MEMS microphones to bring superior experiences to a wide range of consumer devices such as TWS and ear-cup headphones, laptops, tablets, conferencing systems, smartphones, smart speakers, hearing AIDS and even cars.
Today, we live in an exciting time where AI is revolutionizing everyday life, and tools like ChatGPT are redefining productivity through intuitive text and voice interactions. As AI systems continue to advance, traditional business models, beliefs, and assumptions are being challenged. What role does voice play in the emerging AI ecosystem? As business leaders, do we need to rethink our beliefs? Will the rise of generative AI reduce the importance of high-quality voice input, or will high-quality voice input become necessary for widespread adoption of AI services and personal assistants?
Ai, from right-hand man to best friend
It is only natural that humans will adapt their answers to the format of the question as well as the content of the question. The human voice provides a variety of clues that can be used to determine the questioner's age, gender, social and cultural background, and emotional state. In addition, identifying the environment (such as airports, offices, traffic, or physical activities like running) can also help determine the questioner's intentions and adjust answers accordingly for better conversation.
Despite advances in AI capabilities, it is still believed that AI-based assistive tools lack the ability to correctly predict a human's intention to ask a question or how a particular piece of information will be interpreted. To improve human-computer interaction, AI should consider three key factors when making rhetorical choices: knowledge of the listener, the listener's emotional state, and the environmental context.
In many cases, the received audio signal alone is sufficient to extract useful information and make an appropriate response. For example, consider a phone or audio conference with someone you've never met. What's more, consider how one person's perception of another develops and changes after repeated conversations without the opportunity to communicate in person.
Recent research has shown that even small changes in an AI's verbal response style can lead to noticeable changes in the AI's social ability and personality. It is reasonable to assume that, given the right level of sound input, future AI systems will be able to function as effective partners, exhibiting the behavior of human friends, such as asking and really listening for answers, or just listening and reserving judgment when appropriate.
How do humans experience audio signals?
Like any verbal communication, audio messaging uses words and text to convey thoughts, emotions, and opinions. In addition, other communication elements such as pitch, speed, volume, and background noise also affect the overall perception of information.
From a scientific perspective, the human ear perceives audio signals based on two key factors: frequency and sound pressure level. The sound pressure level (SPL), in decibels (dBSPL), represents the amplitude of the sound pressure oscillating around the ambient atmospheric pressure. The sound pressure level of 100dBSPL is equivalent to the loud noise of a lawn mower or helicopter. The lowest point in the sound pressure level range (0dB) is equivalent to a sound pressure oscillation of 20µPa, which represents the hearing threshold for a healthy young person with optimal hearing at a frequency of 1kHz. All human sounds associated with language fall into the 100Hz to 8kHz frequency band. According to ISO 226:2023, the corresponding threshold for human hearing is shown in Figure 1.
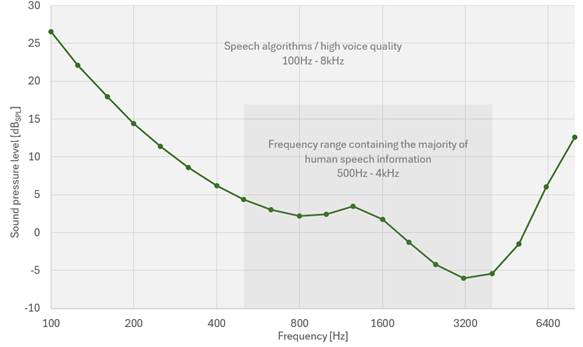
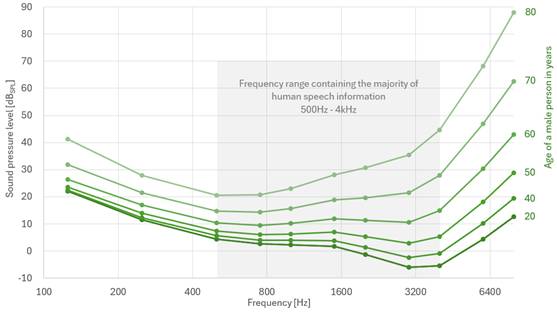
As most of us know, humans' hearing thresholds decline with age, as shown in Figure 2.
Is current audio hardware sufficient to meet the needs of future AI?
Now that we have a better understanding of how humans perceive audio signals, let's revisit the original question of what audio input quality current and future AI will need in order to be indistinguishable from humans.
Most consumer devices on the market today use MEMS microphones to record audio signals. MEMS microphones are the primary audio capture technology for AI personal assistants, and devices using AI assistant technology are now beginning to be sold on the market.
The recording quality of a MEMS microphone depends on its dynamic range. The upper limit of the dynamic range is determined by the acoustic overload point (AOP), which defines the distortion performance of the microphone at high sound pressure levels. The self-noise of the microphone determines the lower limit of its dynamic range. A measure of a microphone's self-noise is the signal-to-noise ratio (SNR), which defines the ratio between the microphone's self-noise and its captured signal (sensitivity). However, for the purposes of our discussion, the SNR is somewhat inappropriate because the self-noise of the SNR uses A-weighting, which is defined based on A human's ability to perceive an audio signal.
If the intended recipient of the audio signal is an AI, the associated microphone's equivalent noise level (ENL) is a more appropriate parameter to measure performance, as it ignores the human perception factor of the recorded sound. The equivalent noise level ENL refers to the signal produced by the microphone in the absence of an external sound source. The equivalent noise level ENL, in decibels (dBSPL), represents the sound pressure level at the same voltage as the microphone's self-noise.
It is worth noting that any sound information below the equivalent noise level ENL is essentially lost and cannot be recovered, regardless of the sound processing method adopted at the later stage. Therefore, if no other element in the audio link introduces noise before the signal reaches the AI algorithm, the microphone ENL can be considered the hearing threshold for the AI algorithm. It should be noted that this is a highly simplified assumption, as there are often many other components in the audio chain, including sound channels, waterproof protective films, and audio processing links.
Refer to Figure 3 for an intuitive comparison of the equivalent noise level ENL curve of the two MEMS microphones with the human hearing threshold.
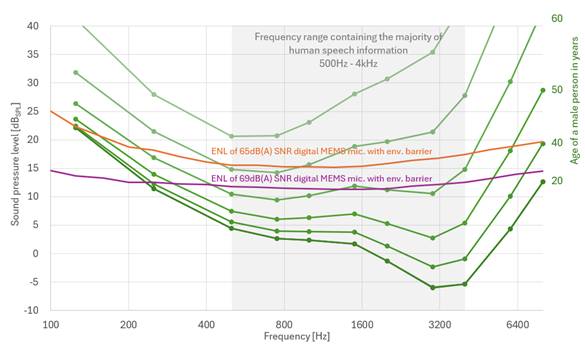
The purple line below represents the equivalent noise level ENL curve of Infineon's latest high-end digital microphone, which features an innovative protective design for dust and water resistance. This microphone represents the current state of the art and was only released on high-end tablets this year. We expect comparable performance microphones to appear on high-end smartphones by the end of the year. It is worth noting that reducing the microphone's self-noise by 5-10dB is a major achievement, especially considering that the sound pressure is expressed using a logarithmic scale.
While Infineon has made significant progress in reducing the self-noise of high-end MEMS microphones, there is still a big gap in the ability of microphones to distinguish low pressure levels compared to the human ear. The vicinity of 2kHz, in particular, is critical to ensuring a high level of sound clarity for human listeners. The gap between a young person's hearing ability and Infineon's state-of-the-art microphones is more than 12dBSPL. Compared to the microphones used in today's high-end phones, the gap is significantly larger, reaching 17dBSPL. Again, it's important to note that this assessment only takes into account self-noise from MEMS microphones and does not take into account additional noise sources in the audio chain that further degrade overall performance.
The limitations of current MEMS microphone technology are most pronounced in the frequency range that contains most human speech information (500Hz-4kHz). Even the most advanced MEMS microphones on the market only have the sound understanding of a 60-year-old. Based on the available data, it is reasonable to expect that AI virtual assistants using the latest MEMS microphone technology will have hearing impairments similar to those experienced by the elderly, especially in situations where conversations need to be read in noisy environments or at a distance.
Summary and prospect
The rapid development of artificial intelligence will not slow down, but will accelerate the development of MEMS microphones to a higher signal-to-noise ratio. While the latest MEMS microphones are not yet able to match the audio quality of the human ear, Infineon's progress in reducing the microphone's self-noise benefits existing and future AI. Further improvements to audio links will be key to enhancing AI capabilities such as ambient resolution, contextual understanding, emotional awareness, speaker recognition, and recording of multi-person conversations. With better audio inputs, the way AI interacts with humans will match, or even match, the way humans interact with each other.
In addition, increased levels of human-computer interaction will enable new AI-based use cases and services. For example, imagine a future Microsoft Copilot that not only summarizes the content of team meetings, but also provides an overall assessment of the atmosphere of the conversation. Future AI-assisted features may be based on human voice and audio, highlighting highlights or ranking them in order of importance. In addition, coaching features can be added to provide users with useful suggestions to help them better steer future conversations in the desired direction.
Imagine an AI that could conduct the first round of interviews with new job candidates, or identify speakers based on audio alone, with a level of security sufficient for online shopping.
All of this is likely to be just a small part of a future in which AI listening abilities match or exceed those of humans. With our enhanced MEMS microphone solutions, Infineon is proud to be part of this exciting journey.
免责声明: 本文章转自其它平台,并不代表本站观点及立场。若有侵权或异议,请联系我们删除。谢谢! Disclaimer: This article is reproduced from other platforms and does not represent the views or positions of this website. If there is any infringement or objection, please contact us to delete it. thank you! |

WeChat Official Account

WeChat Service
 Email
Email QQ
QQ 13823761625
13823761625
